How the "Research Chat" Works
A technical deep-dive into the Retrieval-Augmented Generation (RAG) pipeline enabling accurate, cited answers from my PhD research.
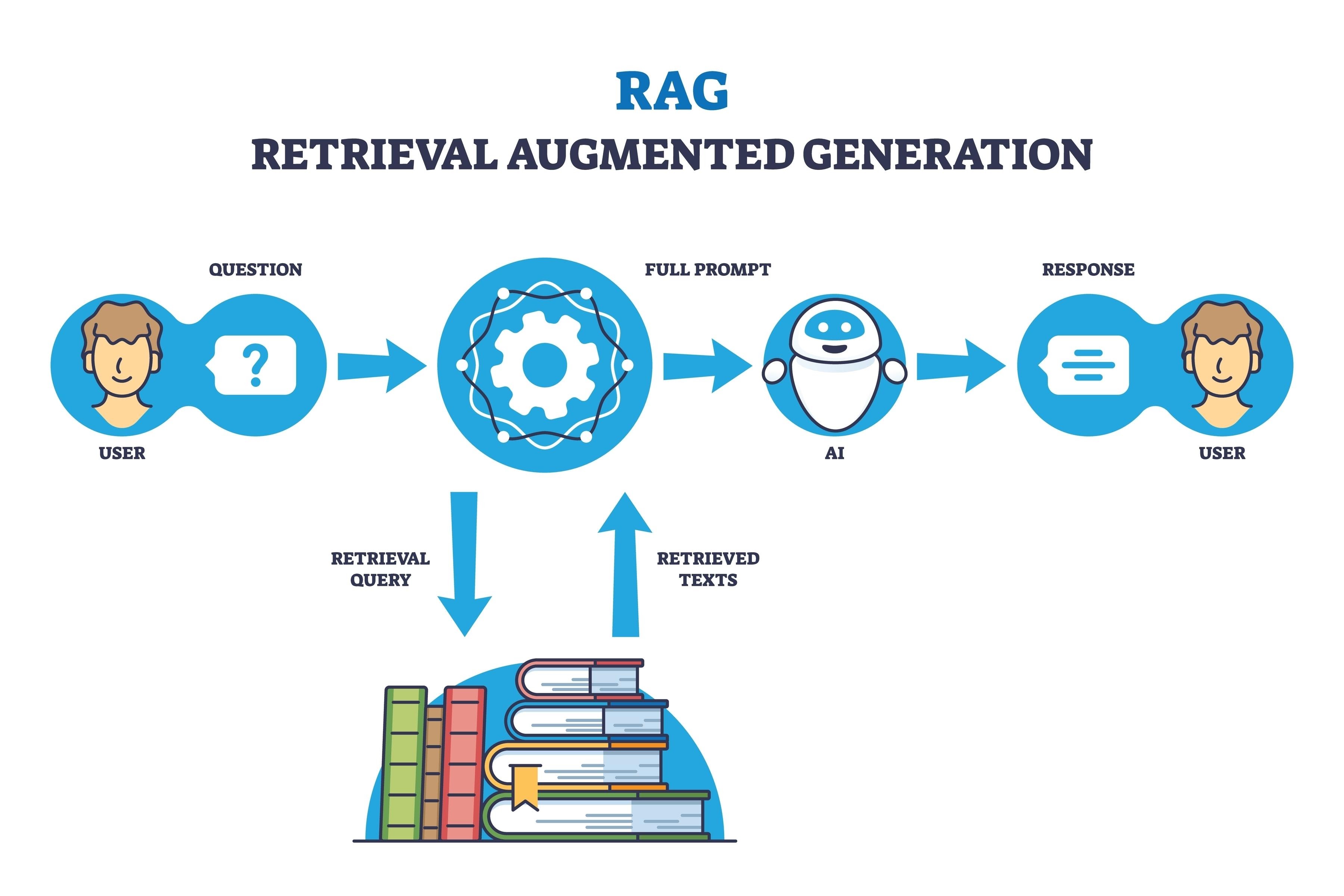
Data Flow Pipeline
1. Ingestion
Python parses PDFs & matches BibTeX citations.
2. Embedding
Google GenAI converts text to 768-dim vectors.
3. Retrieval
Supabase finds relevant chunks via Cosine Similarity.
4. Generation
Gemini 2.5 Flash answers using the retrieved context.
Why RAG?
Standard LLMs like ChatGPT are trained on general internet data and often hallucinate when asked about specific, private documents. Retrieval-Augmented Generation (RAG) solves this by forcing the AI to "read" my actual thesis before answering.
Technical Stack
🎨 Frontend
Next.js 14 (App Router), Tailwind CSS, Vercel AI SDK (React).
⚙️ Backend
Supabase (PostgreSQL + pgvector), Google Gemini API.
📚 Ingestion
Python 3.10 script with pypdf and bibtexparser running on a local Linux NUC.
The "Context Stuffing" Strategy
When you submit a query, the backend doesn't just ask the AI. It constructs a specialized prompt containing the most relevant 5,000 characters from my work:
This ensures every answer is grounded in fact and includes precise citations.
Try It Out
Ready to explore my research? Ask about cooperative robotics, POMCP, particle filters, or urban search and tracking.
Launch Research Chat →